해당 글은 코드잇 강의를 참고하여 작성되었습니다.
- 새로운 값 계산하기
- 새로운 column만들기

예시
- 문자열 필터링
| df['column명'].str.contains('찾는 문자열') | 해당 문자열을 포함하는 전체 column들(boolean형태) |
| df['column명'].str.startswith('찾는 문자열') | 해당 문자열이 맨처음에 나오는 전체 column들(boolean형태) |

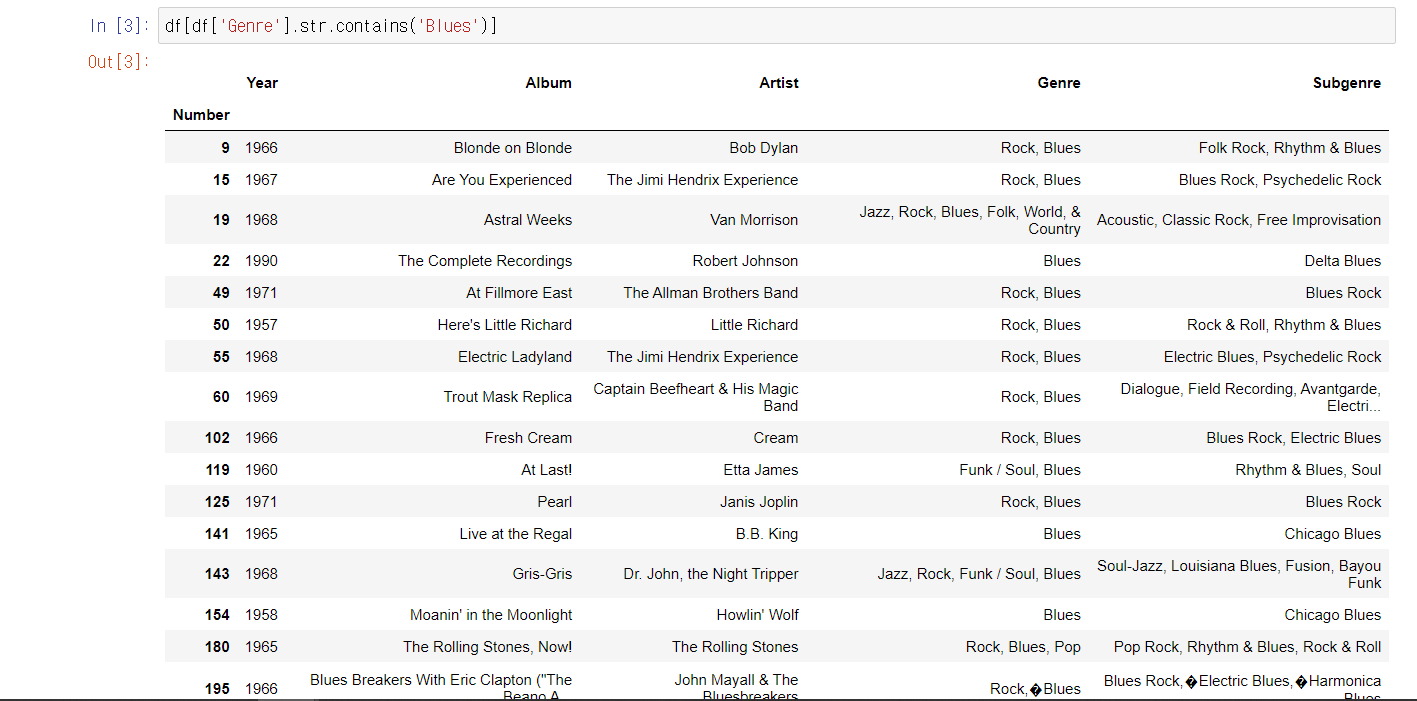

- 문자열 분리
- str.split('나누는 기준', n=x) → 기본적으로 나누는 기준은 공백


- 카테고리로 분류


- groupby
- .max는 오류발생
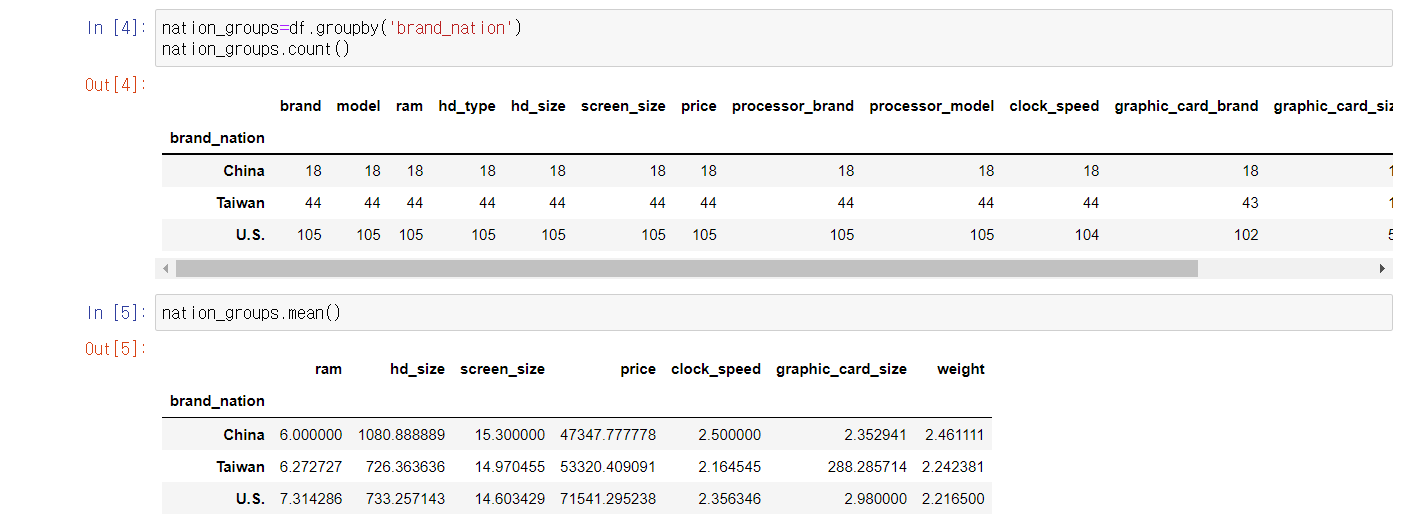


문제 :
groupby 문법을 사용해서 '여성 비율'이 높은 순으로 직업을 나열해 보세요.
DataFrame이 아닌 Series로, 'gender'에 대한 값만 아래와 같이 출력되어야 합니다.

정답 :
import pandas as pd df = pd.read_csv('data/occupations.csv') # 코드를 작성하세요. occupation_group = df.groupby('occupation') df.loc[df['gender'] == 'M', 'gender'] = 0 df.loc[df['gender'] == 'F', 'gender'] = 1 occupation_group.mean()['gender'].sort_values(ascending=False)
- 데이터 합치기(merge)
- inner join (두 프레임이 겹치는 것만 합친다) → 교집합
- left outer join
- right outer join
- full outer join → 합집합


'데이터 > 데이터사이언스입문' 카테고리의 다른 글
| 4.2 데이터 클리닝 (0) | 2021.07.13 |
|---|---|
| 4.1 좋은 데이터의 기준 (0) | 2021.07.13 |
| 3.4 Exploratory Data Analysis (0) | 2021.07.10 |
| 3.3 통계 기본 상식 (0) | 2021.07.09 |
| 3.2 Seaborn 시각화 (0) | 2021.07.09 |

