해당 글은 코드잇 강의를 참고하여 작성되었습니다.
- Boosting
- 성능이 안 좋은 모델들을 사용한다
- 먼저 만든 모델들의 성능이, 뒤에 있는 모델이 사용할 데이터 셋을 바꾼다
- 모델들의 예측을 종합할 때, 성능이 더 좋은 모델의 예측을 더 반영한다.
- 성능이 안 좋은 약한 학습자들을 합쳐서 성능을 극대화한다.
- 에다 부스트
- stump : 질문 노드가 1개인 트리
- 성능이 좋지 않은 결정 스텀프를 많이 만든다.
- 각 스텀프는 전에 왔던 스텀프들이 틀린 데이터들을 더 중요하게 맞춘다.
- 예측을 종합하여 성능이 좋은 스텀프의 의견 비중을 더 높게 반영한다.
- 스텀프 성능 계산하기
- 중요도 열을 생성하고 합은 항상 1로 유지한다.
- 질문의 지니 불순도를 계산해 지니 불순도가 가장 낮은 질문을 선택하고 아래 식으로 계산한다.
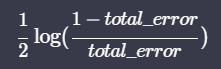 total error는 틀리게 예측한 모든 데이터 중요도의 합
total error는 틀리게 예측한 모든 데이터 중요도의 합
- 데이터 중요도 바꾸기
- 틀리게 예측한 데이터의 중요도를 높여준다.

- 맞게 예측한 데이터의 중요도는 낮춰준다.

- 둘 다 성능이 0일 때 1
- 스텀프가 데이터를 반 이상만 맞추면 틀린 데이터는 원래 중요도에 1보다 큰 값을 곱하니까 원래 값보다 커지고
- 구한 중요도를 합이 1이 되도록 조정한다. (각 데이터의 중요도/ ∑데이터의 중요도)
- 스텀프 추가하기
- 새로 데이터 셋을 만든다
- 중요도를 활용해 기존과 같은 크기의 데이터 셋을 만든다.
- 새 데이터 셋으로 스텀프를 학습시켜 원래의 데이터 셋에 스텀프를 추가한다.
- 위를 반복
- 예측하기
- scikit-learn으로 에다 부스트 구현하기

from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
import pandas as pd
# 데이터 셋 불러 오기
cancer_data = load_breast_cancer()
X=pd.DataFrame(cancer_data.data, columns=cancer_data.feature_names)
y=pd.DataFrame(cancer_data.target, columns=['class'])
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=5)
y_train = y_train.values.ravel()
model=AdaBoostClassifier( n_estimators=50, random_state=5)
model.fit(X_train,y_train)
predictions=model.predict(X_test)
score=model.score(X_test,y_test)
# 출력 코드
predictions, score



