<해당 글은 혼자 공부하는 머신러닝+딥러닝을 공부하고 정리한 내용입니다.>
1. 타깃을 모르는 비지도 학습
- 비지도 학습 : 타깃이 없을 때 사용하는 머신러닝 알고리즘
2. 과일 사진 데이터 준비하기
#주피터 노트북이 아닌 코랩에서만 이 코드로 다운로드 가능
#주피터 노트북일 경우 직접 다운로드 해야 함
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
- 파일에서 데이터 로드
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')
print(fruits.shape)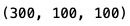
- 이 배열의 첫 번째 차원은 샘플의 개수를 나타내고, 두 번째 차원은 이미지 높이, 세 번째 차원은 이미지 너비입니다.
- 첫 번째 이미지의 첫 번째 행을 출력하기 위해 처음 2개의 인덱스를 0으로 지정하고 마지막 인덱스는 지정하지 않거나 슬라이싱 연산자를 쓰면 첫 번째 이미지의 첫 번째 행을 모두 선택할 수 있다.
print(fruits[0, 0, :])
- imshow() 함수를 사용하면 넘파이 배열로 저장된 이미지를 쉽게 그릴 수 있다. 흑백 이미지이므로 cmap 매개변수를 gray로 지정
plt.imshow(fruits[0], cmap='gray')
plt.show()
- 보통 흑백 샘플 이미지는 바탕이 밝고 물체가 짙은 색인데, 이 흑백 이미지는 사진으로 찍은 이미지를 넘파이 배열로 변환할 때 반전시킨 것. 그 이유는 우리의 관심 대상이 사과이기 때문
- 보기 좋게 다시 반전 시키고자 하면 gray_r로 지정
plt.imshow(fruits[0], cmap='gray_r')
plt.show()
- 위 그림에서 밝은 부분이 0에 가깝고 짙은 부분이 255에 가까운 값이라는 것 기억하기
- 이 데이터는 사과, 바나나, 파인애플이 각각 100개씩 들어있으므로 출력해보기
#subplots는 여러 개의 그래프를 배열처럼 쌓을 수 있게한다.
#subplots함수의 두 매개변수는 여러 개의 그래프를 쌓을 행과 열을 지정
#여기서는 하나의 행과 2개의 열 지정
fig, axs = plt.subplots(1, 2)
#반환된 axs는 2개의 서브 그래프를 담고 있는 배열
axs[0].imshow(fruits[100], cmap='gray_r')
axs[1].imshow(fruits[200], cmap='gray_r')
plt.show()
3. 픽셀값 분석하기
- 100×100을 펼쳐서 10000인 1차원 배열로 나누면 이미지 출력은 어렵지만 계산할 때 편리하다.
- fruits배열에서 순서대로 100개씩 선택하기 위해 슬라이싱 연산자를 사용, 이후 reshape메서드를 사용해 두 번째 차원과 세 번째 차원을 합친다. 첫 번째 차원을 -1로 지정하면 자동으로 남은 차원을 할당한다. 첫 번째 자원이 샘플 개수
apple = fruits[0:100].reshape(-1, 100*100)
pineapple = fruits[100:200].reshape(-1, 100*100)
banana = fruits[200:300].reshape(-1, 100*100)
print(apple.shape)
- 각각의 배열에 들어 있는 샘플의 픽셀 평균값을 계싼하기 위해 mean() 메서드를 사용, 샘플마다 픽셀의 평균값을 계산해야 하므로 mean()메서드가 평균을 계산할 축을 지정해야 하는데, axis=0으로 하면 첫 번째 축인 행을 따라 계산하고 1로 지정하면 두 번째 축인 열을 따라 계산한다.
- 우리가 필요한 것은 샘플의 평균값인데, 샘플을 모두 가로로 값을 나열했기 때문에 axis=1로 지정하여 평균을 계산할 것이다.
print(apple.mean(axis=1))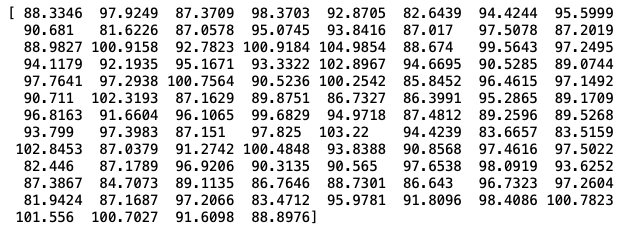
- 히스토그램으로 확인해보기
#alpha를 1보다 작게하면 투명해진다.
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
#legend를 사용하면 어떤 과일의 히스토그램인지 범례를 만들 수 있다.
plt.legend(['apple', 'pineapple', 'banana'])
plt.show()
- 사과와 파인애플은 많이 겹쳐있어 픽셀값만으로는 구분하기 쉽지 않아 샘플의 평균값이 아닌 픽셀별 평균값을 비교해본다.
- 픽셀의 평균을 계산하기 위해서 axis=0으로 지정하고 bar함수를 통해 막대그래프로 그려본다.
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()
- 픽셀 평균값을 100×100 크기로 바꿔서 이미지처럼 출력하여 위 그래프와 비교할 수 있다. 픽셀을 평균 낸 이미지를 모든 사진을 합쳐 놓은 대표 이미지로 생각할 수 있다.
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()
4. 평균값과 가까운 사진 고르기
- 사과 사진의 평균값이 apple_mean과 가장 가까운 사진을 고르기 위해 절댓값 오차를 사용할 수 있다. fruits배열에 있는 모든 샘플에서 apple_mean을 뺀 절댓값의 평균을 계산하면 된다.
#abs는 절댓값을 계산하는 함수
abs_diff = np.abs(fruits - apple_mean)
#abs_diff는 (300,100,100)크기의 배열
#따라서 각 샘플에 대한 평균을 구하기 위해 axis에 두 번째 세 번째 차원을 모두 지정
abs_mean = np.mean(abs_diff, axis=(1,2))
#이렇게 계산한 abs_mean은 각 샘플의 오차 평균이므로 크기가(300,)인 1차원 배열
print(abs_mean.shape)
- 그다음 이 값이 가장 작은 순서대로 100개 고르면 apple_mean과 오차가 가장 작은 샘플 100개를 고르는 것
- np.argsort 함수가 반환한 인덱스 중에서 처음 100개를 선택해 10×10격자로 이루어진 그래프를 그려본다.
#argsort는 작은 것에서 큰 순서대로 나열한 abs_mean 배열의 인덱스 반환
apple_index = np.argsort(abs_mean)[:100]
#subplots함수로 100개의 서브 그래프를 만든다.
#figsize를 지정하여 전체 그래프의 크기를 지정
fig, axs = plt.subplots(10, 10, figsize=(10,10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
#좌표축을 그리지 않음
axs[i, j].axis('off')
plt.show()
- 비슷한 샘플끼리 그룹으로 모으는 작업을 군집이라 하고 이는 대표적인 비지도 학습 작업 중 하나이다. 그리고 군집 알고리즘에서 만든 그룹을 클러스터라고 부른다.
- 위와 같은 방법으로는 타깃값을 알 수 없어 샘플의 평균값을 알 수 없다는 한계가 있다.
5. 비슷한 샘플끼리 모으기
- 타깃값이 없을 때 데이터에 있는 패턴을 찾거나 데이터 구조를 파악하는 머신러닝 방식을 비지도 학습이라고 한다.
- 대표적인 비지도 학습 문제가 군집, 군집이란 비슷한 샘플끼리 그룹으로 모으는 작업
- 이 절에서는 샘플을 알고 있었지만 현실을 그렇지 않으므로 다른 방법 모색 필요
'데이터 > 머신러닝' 카테고리의 다른 글
| Chapter 06-3 주성분 분석 (0) | 2022.03.15 |
|---|---|
| Chapter 06-2 k-평균 알고리즘 (0) | 2022.03.15 |
| Chapter 05-3 트리의 앙상블 (0) | 2022.03.12 |
| Chapter 05-2 교차검증과 그리드 서치 (0) | 2022.03.10 |
| Chapter 05-1 결정 트리 (0) | 2022.03.10 |



