해당 글은 코드잇 강의를 참고하여 작성되었습니다.
- 분류문제
- 선형 회귀로도 풀 수 있지만 예외적인 데이터의 변화에 민감하게 반응해서 잘 사용하지 않는다.
- 로지스틱 회귀
- 일차 함수가 아닌 시그모이드 함수를 사용한다.
- 시그모이드 함수 : 0≤X≤1

- 가설 함수
- 분류를 구별하는 경계선 = Decision Boundary


위와 같은 의미의 함수
- 분류를 구별하는 경계선 = Decision Boundary



- 로지스틱 회귀 손실 함수
- 로그 손실 사용

- 로지스틱 회귀 손실 함수


- 로지스틱 회귀 경사 하강법
- 선형회귀와 식이 같다! 단지 가설 함수 hθ(x)가 시그모이드 함수일뿐
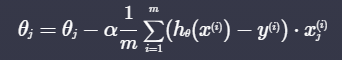
import numpy as np def sigmoid(x): """시그모이드 함수""" return 1 / (1 + np.exp(-x)) def prediction(X, theta): """로지스틱 회귀 가정 함수""" # 지난 과제에서 작성한 코드를 갖고 오세요 return sigmoid(X @ theta) def gradient_descent(X, theta, y, iterations, alpha): """로지스틱 회귀 경사 하강 알고리즘""" m = len(X) # 입력 변수 개수 저장 for _ in range(iterations): # 코드를 쓰세요 error = prediction(X, theta) - y theta = theta - alpha / m * (X.T @ error) return theta # 입력 변수 hours_studied = np.array([0.2, 0.3, 0.7, 1, 1.3, 1.8, 2, 2.1, 2.2, 3, 4, 4.2, 4, 4.7, 5.0, 5.9]) # 공부 시간 (단위: 100시간) gpa_rank = np.array([0.9, 0.95, 0.8, 0.82, 0.7, 0.6, 0.55, 0.67, 0.4, 0.3, 0.2, 0.2, 0.15, 0.18, 0.15, 0.05]) # 학년 내신 (백분률) number_of_tries = np.array([1, 2, 2, 2, 4, 2, 2, 2, 3, 3, 3, 3, 2, 4, 1, 2]) # 시험 응시 횟수 # 목표 변수 passed = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]) # 시험 통과 여부 (0: 탈락, 1:통과) # 설계 행렬 X 정의 X = np.array([ np.ones(16), hours_studied, gpa_rank, number_of_tries ]).T # 입력 변수 y 정의 y = passed theta = [0, 0, 0, 0] # 파라미터 초기값 설정 theta = gradient_descent(X, theta, y, 300, 0.1) # 경사 하강법을 사용해서 최적의 파라미터를 찾는다 theta
- 분류가 3개 이상일 때
- 각각의 분류의 가설 함수를 계산해 가장 높은 확률로 분류
**로지스틱 회귀는 정규방정식으로 구할 수 없다. 단순히 미분만으로 convex를 구할 수 없기 때문
- scikit-learn으로 로지스틱 회귀 구현
# 필요한 라이브러리 import
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import pandas as pd
wine_data = datasets.load_wine()
""" 데이터 셋을 살펴보는 코드
print(wine_data.DESCR)
"""
# 입력 변수를 사용하기 편하게 pandas dataframe으로 변환
X = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
# 목표 변수를 사용하기 편하게 pandas dataframe으로 변환
y = pd.DataFrame(wine_data.target, columns=['Y/N'])
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=5)
y_train=y_train.values.ravel()
logistic_model=LogisticRegression(solver='saga', max_iter=7500)
logistic_model.fit(X_train, y_train)
y_test_predict=logistic_model.predict(X_test)
# 테스트 코드
score = logistic_model.score(X_test, y_test)
y_test_predict, score'데이터 > 머신러닝' 카테고리의 다른 글
| 3.2 정규화 (0) | 2021.07.24 |
|---|---|
| 3.1 데이터 전처리 (0) | 2021.07.23 |
| 2.3 다항 회귀(Polynomial Regression) (0) | 2021.07.22 |
| 2.2 다중 선형 회귀(Multiple Linear Regression) (0) | 2021.07.22 |
| 2.1 선형 회귀(Linear Regression) (0) | 2021.07.21 |



